

AWS Lambda Invocation Models
Why How Your Function Is Invoked Matters More Than the Function Itself

Most Lambda failures in production are not caused by bad code.
They’re caused by choosing the wrong invocation model.
Engineers obsess over runtimes, memory size, cold starts, and frameworks but quietly gloss over how the function is triggered. That’s a mistake. Invocation model determines who waits, who retries, who owns failure, how permissions are enforced, and how your system behaves under load.
AWS Lambda has three fundamentally different invocation models:
Synchronous invocation
Asynchronous invocation
Event Source Mapping
They may look similar on a diagram “event goes in, function runs” but architecturally, they are completely different beasts.
This article breaks them down not as features, but as contracts between systems.
Why Invocation Models Matter in Real Systems
Think of Lambda not as a function, but as a worker. Invocation model answers questions like:
Who is knocking on the door?
Does the caller wait outside or leave immediately?
If the worker fails, who is responsible for retrying?
What happens when work piles up faster than it can be processed?
These questions define latency, reliability, and cost.
Get them wrong, and you end up with brittle APIs, runaway retries, duplicated data, or silent message loss. Get them right, and Lambda becomes boring in the best possible way.
Let’s walk through each model carefully.
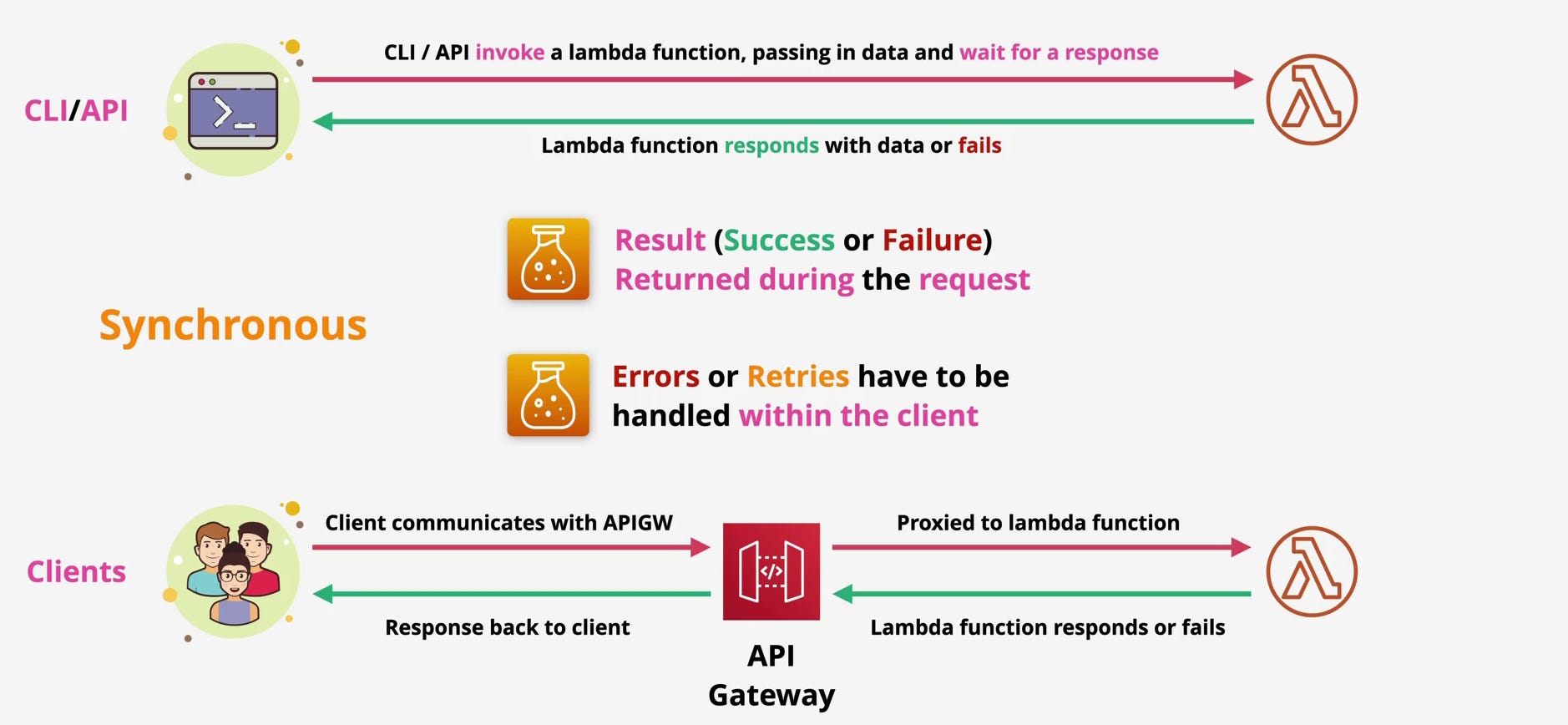
Synchronous Invocation: “I’ll Wait for the Answer”
Synchronous invocation is the simplest mental model and the most dangerous when misused.
In this model, the caller invokes Lambda and waits. The function executes, and the response success or failure is returned directly to the caller. Nothing else moves forward until Lambda finishes.
This is how Lambda behaves when invoked through the AWS CLI, SDKs, or API Gateway in a request–response flow.
At the API level, this behavior corresponds to InvocationType=RequestResponse.
What Actually Happens in a Synchronous Flow
Consider an HTTP request through API Gateway:
A client sends a request to an API Gateway endpoint.
API Gateway invokes the Lambda function synchronously.
Lambda loads the execution environment (or reuses one), runs your handler, and returns a payload.
API Gateway forwards that payload back to the client as an HTTP response.
The entire chain is blocking. If Lambda takes 200 milliseconds, the client waits 200 milliseconds. If Lambda errors, the client sees the error. If Lambda times out, the client experiences a timeout.
There is no buffering. No retry by AWS. No safety net.
While clients or upstream integrations may retry requests on their own, Lambda provides no retry guarantees in synchronous mode.
This makes synchronous invocation ideal for interactive workflows places where a human or upstream service genuinely needs an immediate answer.
Authentication checks.
Form validation.
Pricing calculations.
Short-lived CRUD operations.
These are all appropriate uses.
Where Engineers Get This Wrong
The problem starts when synchronous invocation is used for work that does not need to be synchronous.
Long-running jobs.
File processing.
Fan-out workflows.
Anything that might spike unpredictably.
When Lambda is synchronous, you own retries. You own backoff. You own partial failures. API Gateway will not retry for you. The SDK will not magically make this reliable.
Even worse, synchronous Lambdas are constrained by hard timeouts. API Gateway has its own timeout limits. If your Lambda finishes but API Gateway has already given up, the client sees failure even though the work succeeded.
That’s how you end up with duplicate writes, confused users, and support tickets that start with “sometimes it works.”
Synchronous invocation should feel uncomfortable unless the use case truly demands it.
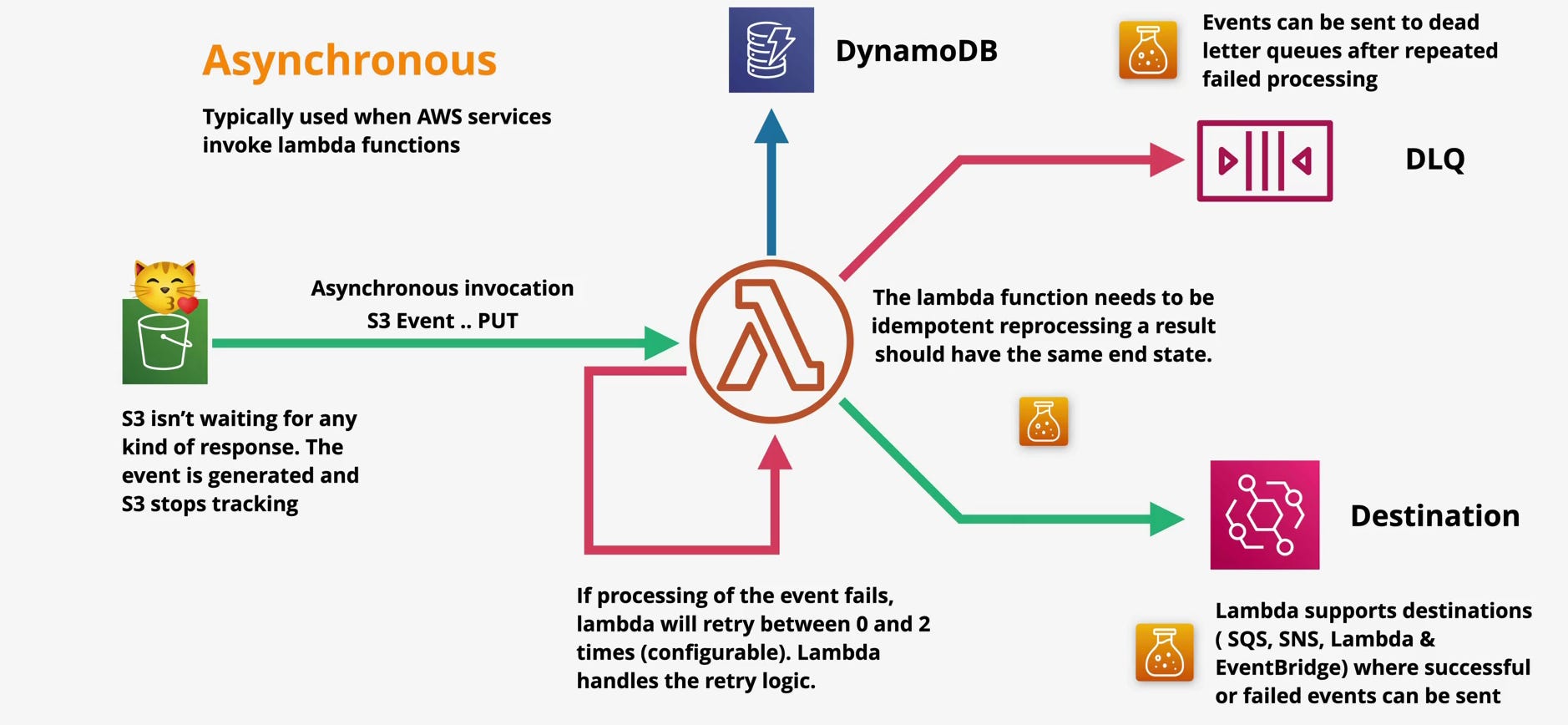
Asynchronous Invocation: “Here’s the Work -You Handle It”
Asynchronous invocation flips the responsibility model.
The caller sends an event to Lambda and walks away. AWS acknowledges receipt, queues the event internally, and invokes the function later. The caller does not wait for execution, and does not receive the result.
At the API level, this corresponds to InvocationType=Event.
This model is most commonly used when AWS services invoke Lambda - S3, SNS, EventBridge, CloudWatch Events, and others.
How Asynchronous Invocation Actually Works
When an asynchronous event occurs, AWS places it into an internal Lambda-managed queue. Lambda then pulls from that queue and invokes your function.
If the function succeeds, the event is discarded.
If the function fails, Lambda retries automatically.
By default, Lambda retries failed asynchronous invocations up to two additional times, with exponential backoff. This retry behavior is owned by Lambda not the source service and not your code.
What’s often missed is that these retries are time-distributed, not immediate. Failed asynchronous events can be retried over a window of up to several hours, meaning errors may surface long after the original event occurred. This delayed retry behavior is intentional it protects the system from thundering herds but it also means failure handling must account for late-arriving side effects.
That distinction matters.
A Real-World Example That Actually Breaks Systems
Imagine an S3 bucket where users upload images.
Each upload triggers a Lambda function that:
Resizes the image.
Extracts metadata.
Writes records to DynamoDB.
S3 does not care whether your function succeeds. It fires the event and moves on. Lambda owns execution and retries.
If your function crashes halfway say, after resizing but before writing metadata Lambda retries the entire event. If your code is not idempotent, you now have duplicate images, corrupted state, or inconsistent records.
This is why idempotency is not optional in asynchronous Lambdas.
Idempotency Is Not a Buzzword , It’s Survival
An idempotent function can safely process the same event multiple times and produce the same final state.
Without idempotency, retries become data corruption machines.
Common strategies include:
Using deterministic object keys.
Checking for existing records before writing.
Using conditional writes in DynamoDB.
Embedding event IDs and rejecting duplicates.
If you don’t design for retries, Lambda will happily retry you into chaos.
Handling Failure Like an Adult
Retries are not infinite. Eventually, events fail permanently.
This is where failure destinations come in.
Lambda allows you to route failed asynchronous events to destinations such as:
SQS, for later inspection or reprocessing.
SNS, for alerting.
Another Lambda, for custom error handling.
EventBridge, for orchestration or auditing.
Dead Letter Queues (DLQs) are the older mechanism, typically using SQS or SNS. Lambda Destinations are the modern, more flexible replacement.
The key idea is simple: never let failures disappear silently. If you don’t explicitly handle them, AWS will eventually drop the eventand you won’t know until data goes missing.
Event Source Mapping: “I’ll Poll the Work Myself”
Event Source Mapping exists for a specific reason: some services do not push events.
SQS, Kinesis, and DynamoDB Streams don’t invoke Lambda directly. Instead, Lambda creates an internal poller that continuously checks these sources for new records.
This polling mechanism is called an Event Source Mapping.
Why This Model Exists
Queues and streams are pull-based by design. They expose records, not triggers. Lambda adapts to that model by acting as a consumer.
This changes everything about execution behavior.
Lambda decides when to poll.
Lambda decides batch size.
Lambda decides concurrency scaling.
Lambda controls backpressure.
Your function is no longer invoked per event it is invoked per batch.
What This Looks Like in Practice
Take SQS as an example.
Messages arrive in the queue.
Lambda polls the queue and retrieves a batch.
Your function processes the batch.
If processing succeeds, Lambda deletes the messages.
If it fails, the messages become visible again.
This is not fire-and-forget. This is coordinated consumption.
The same model applies to DynamoDB Streams and Kinesis, with ordering guarantees and shard-based parallelism layered on top.
Batching, Scaling, and Backpressure
Event Source Mapping introduces batching to improve efficiency. Instead of invoking Lambda once per message, Lambda processes groups of records together.
This reduces cost but increases blast radius.
If your function fails while processing a batch, the entire batch is retried. That means one bad record can block good ones unless you explicitly handle partial failures.
For SQS-based event source mappings, Lambda now supports partial batch responses, allowing your function to report which individual messages failed while successfully processing others. This capability must be explicitly implemented in your handler logic; without it, Lambda assumes the entire batch failed.
Streams such as Kinesis and DynamoDB Streams do not support partial batch success in the same way. Ordering guarantees mean a single problematic record can stall progress until it is handled or discarded.
Backpressure is another critical concept. If your function slows down, Lambda automatically reduces polling frequency. This protects downstream systems but can cause lag buildup.
Understanding this behavior is essential when processing high-volume streams.
Concurrency and Scaling: Where Invocation Models Really Break Systems
Invocation models directly determine how Lambda scales and how it fails under load.
With synchronous invocation, if concurrency limits are reached, new requests fail immediately. Clients see errors, retries amplify traffic, and outages cascade quickly.
With asynchronous invocation, events are accepted and queued even when concurrency is exhausted. This protects callers, but backlog can silently grow. When capacity returns, Lambda may process hours of delayed work at once, causing unexpected downstream load.
With event source mappings, Lambda tightly controls concurrency and polling rates. Throughput increases gradually, backpressure is applied automatically, and queues or streams absorb spikes instead of your function.
These differences are why the same Lambda function can behave perfectly in one model and catastrophically in another.
Concurrency limits don’t care about your intent. They only care about how you invoke.
Permissions & Security: The Most Misunderstood Difference
Invocation models are not just about execution they define who needs permission to do what.
This is where many IAM designs fall apart.
Asynchronous Invocation Permissions
When a service like S3 or EventBridge invokes Lambda asynchronously, that service pushes the event.
Lambda does not need permission to read from S3 just to receive the event. It only needs permissions if your code explicitly accesses S3 objects or other resources.
The source service needs permission to invoke the Lambda function. That’s it.
This creates a clean security boundary.
Event Source Mapping Permissions
Event Source Mapping flips this model.
Lambda is now the one polling the source. That means Lambda’s execution role must have permission to read from SQS, Kinesis, or DynamoDB Streams.
If permissions are wrong, nothing happens. No errors in your function logs. No failed invocations. Just silence.
This is why Event Source Mapping bugs are so painful to debug: the function never runs.
Understanding this distinction is critical for:
Designing least-privilege IAM roles.
Debugging “Lambda is not triggering” issues.
Maintaining clear security boundaries between services.
Choosing the Right Invocation Model: An Architectural Decision Guide
If you need an immediate response and the caller is a human or synchronous system, use synchronous invocation but keep execution short and predictable.
If the work can happen in the background, requires retries, or is triggered by AWS services, use asynchronous invocation and design for idempotency from day one.
If you are consuming queues or streams and need controlled throughput, ordering, and backpressure handling, Event Source Mapping is the right tool but only if you understand batching, concurrency boundaries, and permissions deeply.
Lambda is not just “serverless compute.” It is a coordination engine.
Invocation models define how systems coordinate work, not just how code executes. When misused, they create distributed systems failures not coding bugs.
Most Lambda outages are not runtime bugs they’re architectural mistakes made on day one.
Choose the model deliberately or it will choose failure for you.
