
Pointers in Go: They’re Not What C Taught You to Fear
Go pointers aren’t scary here’s what they actually do

You open the controller-runtime docs. You’re trying to understand how a Kubernetes reconciler works, and the first function signature you see looks like this:
func (r *PodReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error)Two pointers in one line. The receiver is a pointer. The context carries a pointer under the hood. You’ve seen this pattern in every Kubernetes operator example you’ve looked at, and nobody stops to explain it.
This article is that explanation. By the end, you’ll understand every pointer you encounter in cloud-native Go code and you’ll know exactly why Kubernetes leans on them so heavily.
Hi — this is Pushpit from CloudOdyssey . I write about Cloud, DevOps, Systems Design deep dives and community update around it. If you have not subscribed yet, you can subscribe here.
What a Pointer Actually Is
A variable holds a value directly. An int variable holds an integer. A string variable holds a string. The value lives in memory, at some address.
A pointer holds an address. Not the value itself the location where the value lives.
Think of it this way: a variable is a house with furniture inside. A pointer is a slip of paper with that house’s address written on it. You can hand that slip of paper to ten different people. They can all travel to the same house and rearrange the furniture. When anyone walks in and looks around, they see the current state not a snapshot of what it looked like when you wrote the address down.
Here’s what that looks like in Go:
x := 42 // x is a house, the value 42 is inside
p := &x // p is a slip of paper with x's address
// & means "give me the address of"
fmt.Println(*p) // * means "go to the address and read what's there"
// prints 42
*p = 100 // change the value at that address
fmt.Println(x) // prints 100 — x was changed via the pointerOne thing that Go does differently from C: you cannot do arithmetic on pointers. You cannot write p + 1 to peek at the next memory location. That restriction is intentional. It’s why Go pointers don’t cause the buffer overflows and memory corruption that made C pointers notorious. The pointer either points to something valid, or it points to nil. There is no in-between.
The Two Reasons Pointers Exist
Reason one: you want a function to change the original value.
Go passes everything by value. When you call a function and hand it a struct, Go copies that struct. Whatever the function does to its copy, your original is untouched.
type Service struct {
Name string
Healthy bool
}
// This function changes a copy — the original Service is unaffected
func setHealthyByValue(s Service) {
s.Healthy = true // modifies the copy, not the caller's value
}
// This function changes the original — the pointer connects them
func setHealthyByPointer(s *Service) {
s.Healthy = true // modifies what s points to — the caller sees this
}If you call setHealthyByValue(svc), the function works on a copy. When it returns, svc.Healthy is still false. Call setHealthyByPointer(&svc), and when it returns, svc.Healthy is true. Same code, completely different behaviour.
Reason two: you want to avoid copying large structs.
A v1.Pod in Kubernetes has dozens of nested fields metadata, spec, status, labels, annotations, container specs. Copying that entire struct every time you call a function is wasteful. A pointer is always 8 bytes on a 64-bit system, regardless of how large the struct is.
// Copies the entire Config struct on every call — expensive if Config is large
func configure(c Config) error { ... }
// Passes 8 bytes (the address) — size of Config is irrelevant
func configure(c *Config) error { ... }At the scale Kubernetes operates thousands of reconcile loops per second that efficiency matters. It’s not premature optimisation when the struct has 50 fields and the function is called in a hot path.
The One Real Danger: nil Pointers
A pointer that hasn’t been assigned points to nothing. In Go, that’s called nil. If you try to read or write through a nil pointer, the program panics.
var s *Service // s is nil — it points to nothing
fmt.Println(s.Name) // panic: runtime error: invalid memory address or nil pointer dereferenceThis is the most common pointer error you’ll actually encounter in production Go code. The fix is simple and should become a reflex:
func processService(s *Service) error {
if s == nil {
return fmt.Errorf("service cannot be nil")
}
fmt.Println(s.Name) // safe to dereference here
return nil
}When a nil dereference does happen, Go gives you the exact file, line number, and full stack trace. This is very different from C, where the same mistake gives you a segfault and a core dump with no useful context. Go’s runtime is helpful, even when your code isn’t.
Pointer Receivers: Why the Reconciler Uses *PodReconciler
Back to the opening question. The reconciler method is declared with a pointer receiver:
func (r *PodReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
// r is a pointer to the PodReconciler struct
// r.Client, r.Log, r.Scheme are all accessible here
}If it used a value receiver instead, every call to Reconcile would copy the entire PodReconciler struct. Any changes to r inside the function would be lost when the function returned. The reconciler’s internal client, scheme, and logger would need to be re-established from scratch.
There is one rule worth memorising here, taken directly from Effective Go:
If any method on a type modifies the receiver, use pointer receivers for all methods on that type.
Not some methods. All of them. Mixing pointer and value receivers on the same type creates confusion about which methods see the original and which see a copy. Go permits it, but it leads to subtle bugs that are genuinely hard to track down. Pick one semantic and stay consistent.
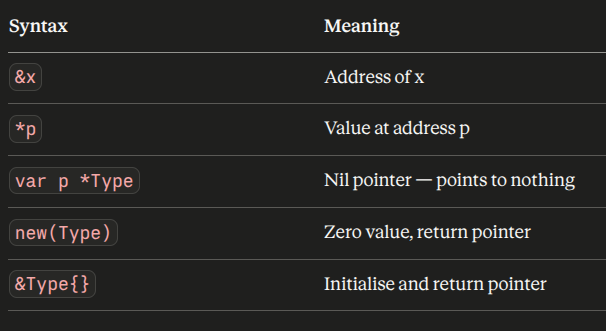
new() vs & — Which One to Use
Go gives you two ways to create a pointer to a new value:
// new() allocates a zeroed Service and returns a pointer
s1 := new(Service) // s1 is *Service, s1.Name is ""
// &Type{} allocates and initialises in one step
s2 := &Service{Name: "api-gateway", Healthy: true}In practice, you’ll use &Service{} roughly 95% of the time. It lets you set initial values in the same expression. new() is useful when you specifically want a pointer to a zero value and you’re going to populate the fields separately — less common, but occasionally the right tool.
In the Cloud Wild
Every Kubernetes resource in controller-runtime is handled via pointer. When your reconciler fetches a Pod, it gets a *v1.Pod. When it updates the status, it’s modifying what that pointer points to, then calling r.Status().Update().
func (r *PodReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
pod := &v1.Pod{} // allocate a Pod to receive the fetched data
// Get populates pod in-place — it needs a pointer to write into
if err := r.Get(ctx, req.NamespacedName, pod); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
// Modify the status field via the pointer
pod.Status.Phase = v1.PodRunning
// Update writes the modified struct back to the API server
if err := r.Status().Update(ctx, pod); err != nil {
return ctrl.Result{}, err
}
return ctrl.Result{}, nil
}The pointer is what makes the update propagate. If pod were a value copy, r.Status().Update() would be sending the API server a local snapshot with no connection to what was fetched. The shared address is the mechanism that keeps the read and the write connected.
This pattern appears in Terraform providers, in Prometheus exporters, in every piece of Go infrastructure tooling you’ll open. Once you see it, you cannot unsee it.
Quick Reference
What’s Next
Next up: methods and interfaces. Methods are how you attach behaviour to types in Go. Interfaces are how Go achieves polymorphism and the rule for how a type satisfies an interface will surprise you if you’re coming from Java or C#. There’s no implements keyword. The compiler figures it out. That single design decision shapes how almost every Go library you’ll ever use is structured.
